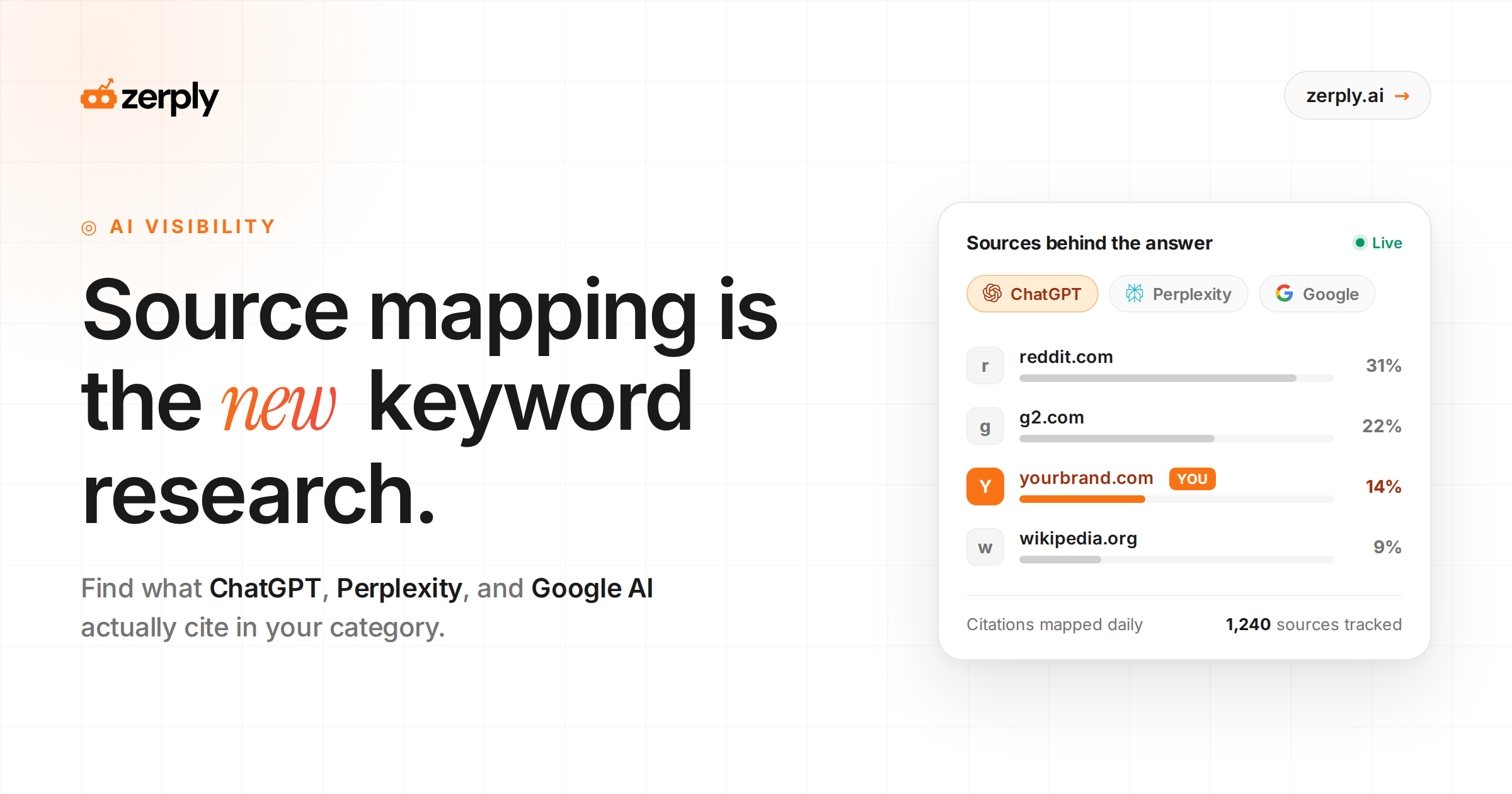
How to Find the Sources ChatGPT, Perplexity, and Google AI Use for Your Category

Buyer discovery now starts before the actual click.
AI answers shape shortlists, frame categories, and narrow vendor consideration before many users ever reach a results page. That changes the job for SEO, PR, and growth teams: ranking still matters, but it is no longer enough.
You might’ve heard that source mapping is the new keyword research, and that the real work is upstream.
Thus, you need to identify your category’s AI Source Set, sort it with a Citation Source Taxonomy, and turn the gaps into a Citation Gap Worklist your team can execute. Let’s look into AI citation sources in detail.
What AI Citation Sources Actually Are
AI citation sources are the domains, pages, passages, and media assets an AI system uses as evidence when generating an answer. They are not the same as backlinks and unlinked brand mentions. Most visibility comes from knowing which external sources AI trusts, and then earning presence across that source set.
Citation vs. Mention vs. Source
A citation is a linked or attributed source used to support a claim in an AI answer.
A mention is an unlinked reference to a brand, product, or concept.
A source is the underlying document or asset retrieved by the model, whether it is cited or not.
That distinction matters because AI search source analysis is passage-driven. A domain can be retrieved but never cited. A brand can be mentioned without becoming supporting evidence. And a well-structured paragraph on a modest page can beat a stronger domain if the claim is clearer and easier to extract.
Why This Isn’t Just SEO With Extra Steps
AI engines do not simply rank pages and quote the winners. This is because retrieval layers differ by engine, filtering happens after retrieval, and corroboration across independent domains often matters more than one strong owned page.
As such, homepages with over 7.9k organic visitors effectively double their AI citation chances when compared to the ones getting 400 odd visitors or less.
That said, source mapping is the new keyword research. Keyword research tells you what people ask. Source mapping tells you which evidence layers shape the answer before the click.
Did You Know: AI platforms drive around 0.15% of all global internet traffic.
How Each Major AI Engine Picks Its Sources
ChatGPT, Perplexity, and Google AI do not choose sources the same way. Each uses a different retrieval and ranking stack, so the same prompt can produce different cited domains, different evidence layers, and different visibility opportunities.
If you want a reliable AI Source Set, you need platform-specific source analysis first.
ChatGPT Search: Bing-Powered Retrieval Layer With a Metadata Gatekeeper
ChatGPT sources are not just a mirror of what it can retrieve. They are filtered before they become citations.
Kevin Indig's analysis of 1.2 million ChatGPT responses found that ChatGPT retrieves roughly 6x more pages than it cites, meaning about 85% of retrieved pages are never used as citations. Pages ranking #1 on Google were cited 3.5x more often than pages outside the top 20. That points to a heavy filtering layer between retrieval and citation.
The pattern gets clearer in Metronyx’s 1,000-query study: Wikipedia accounted for 7.8% of all ChatGPT citations and 47.9% of the top 10 cited sources, while .com domains made up 80.4% and .org domains 11.3%.
ChatGPT also leans heavily on generic search retrieval, with about 88% of citations coming from that ref type.
In practice, that means title clarity, clean framing, explicit entities, and extractable claims decide whether a retrieved page becomes a cited page. So if your content hides the answer deep in the page, or fails to state the claim cleanly, retrieval alone will not save you.
Perplexity: Six-Stage RAG Pipeline With a 0.7 Quality Threshold
Perplexity citations come from a more explicit retrieval workflow. ZipTie’s breakdown of the pipeline describes six stages: query understanding, source retrieval, reranking, passage extraction, synthesis, and citation presentation. That reranking layer matters because weak evidence can be filtered out even after retrieval.
PromptAlpha reports that Perplexity uses a proprietary index of 200B+ URLs, and the reranking threshold sits around 0.7 for quality.
Focus Modes then change what retrieval context gets emphasized. A broad research prompt and a shopping-style prompt do not pull from the same evidence mix.
This is why passage structure matters so much in Perplexity. Direct answer formatting, clean subheads, schema support, and self-contained claims make extraction easier.
As has been documented in dev.to’s case study on Perplexity citations, adding Article, HowTo, FAQPage, and SoftwareApplication schema increased citation rate by about 40%. For Perplexity, good structure is not cosmetic. It is retrieval support.
Google AI Overviews and AI Mode: Two Surfaces, Two Strategies
Google AI has two distinct visibility surfaces, and they behave differently. AI Overviews stay closer to classic ranking logic, while AI Mode acts more like a guided exploration layer. You need a separate strategy for each.
Semrush’s 2026 AI Mode study found that AI Mode sidebars show about 7 unique domains, with 51% overlap with Google’s top 10, 89% domain match, and 80% exact URL alignment. So ranking still matters, but it does not fully determine what gets surfaced.
Search Engine Land reports that 88% of users accept the AI Mode shortlist as-is, 74% choose the top-ranked item, and 64% click nothing.
For AI Overviews, position strongly affects citation probability. Think of AI Overviews like autoplay recommendations and AI Mode like a browse-and-select interface. Both reward strong ranking, but source framing and corroboration still influence which pages become cited evidence.
The Citation Source Taxonomy: Five Archetypes
Most AI citation sources fall into a small set of repeatable source types. The Citation Source Taxonomy helps teams stop treating every cited domain the same way and start routing each source into the right content, PR, community, or partnership motion. That is how raw source logs become an operating model.
As such, a large number of LLM citations originate from listicles, articles, and product pages, which makes format recognition just as important as domain recognition.
Encyclopedic:
These sources confirm entities, definitions, and category framing. They are useful when AI systems need a stable reference layer for who you are, what your category means, and how concepts relate.Community:
Forums, Q&A threads, and expert discussions validate pain points and real-world phrasing. They often show up on comparison prompts where practitioner language matters more than polished copy.Multimodal:
YouTube, webinars, and transcript-rich assets extend your evidence layer beyond text. AtomicAGI’s 2026 PR guide found AI visibility can correlate up to 0.74 with YouTube mentions, which makes multimedia a citation lever, not just a brand channel.Editorial:
Trade publications, explainers, and category listicles are often the most repeatable non-branded citation layer. In B2B SaaS, these are usually the sources that frame “best,” “top,” and “alternatives” prompts.Vendor/Review:
Review sites, comparison hubs, and product directories matter most when buyers move from learning to selection. These sources often dominate shortlist prompts because they compress options into machine-readable comparisons.
The Source Map Method: 5-Step Workflow
The fastest way to find your category’s AI citation sources is to use a repeatable workflow. The goal is not to inspect one prompt or one engine but to build a stable AI Source Set, compare it against competitors, and turn the gaps into action.
Step 1: Define Buyer Prompt Set
Build prompts from real buyer language, not branded vanity terms.
Realistically, cover these five groups: problem-aware, category, comparison, shortlist, and implementation prompts. A category source map built only from “best tools” queries will miss the evidence layers shaping earlier discovery.
Make sure every prompt runs across all four major surfaces: ChatGPT Search, Perplexity, Google AI Overviews, and Google AI Mode. Source sets shift by buyer stage and by engine. That variation is the point.
Step 2: Run Across All Four Major Surfaces
Log every run the same way: prompt, cited domains, cited URLs, content format, source archetype, whether your brand is cited or merely mentioned, and the angle of the extracted claim. Consistency is what makes comparison possible later.
Step 3: Aggregate the Category Citation Graph
Once you have enough runs, combine them into a Category Citation Graph. Look for recurring domains, recurring formats, recurring entities, and platform-specific outliers. The graph shows what the category trusts, not just what one answer happened to surface.
Drift matters here. A single snapshot will mislead you because source sets change over time. That is why repeated logging is part of the method, not a nice-to-have.
Step 4: Run Citation Gap Analysis vs Competitors
Now compare your presence against competitors across source coverage, archetypes, recurring prompts, evidence formats, and corroboration depth. This becomes your Citation Gap Worklist. The point is not to chase every source. It is to find the repeat sources you are absent from and the formats you are under-serving.
Step 5: Convert the Source Set Into Content + PR Plan
Turn the worklist into verbs. Comment in community threads that already shape answers. Pitch editorial and listicle sources that recur in your category. Claim and improve review and directory profiles. Respond to evaluation prompts with cleaner owned assets. Engage in multimodal channels. Publish extractable, schema-supported pages that can be cited directly.
This is not content for content’s sake. It is targeted source acquisition and corroboration. If you want one place to manage prompt runs, source logging, drafting, publishing, and AI visibility tracking, Zerply is built for that consolidated workflow.
Tools and Measurement: What to Track Weekly
If you want AI search source analysis to become operational, you need a simple weekly measurement model. The goal is not to track everything but to monitor whether your AI citation sources are expanding, whether coverage is stable across engines, and whether your team is closing source gaps faster than competitors.
Manual vs Automated Tracking
Manual tracking works for a small prompt set. It breaks when you need cross-engine comparison, recurring audits, and drift detection. Centralizing AI visibility tracking in one workflow is usually cleaner than managing spreadsheets, screenshots, and disconnected tools.
That is where a consolidated platform aligned with Google Search Console data becomes useful.
The Five Metrics to Watch
Track only five metrics:
Citation count
Share of voice
Gap count
Source set drift
Mention sentiment
Pro Tip: Do not overvalue vanity prompt wins, raw mention volume without citation context, or backlink growth as a proxy for citation performance.
Five Mistakes That Quietly Kill AI Citation Performance
Most AI citation losses do not come from one major technical failure. They come from small operating mistakes that distort how teams measure visibility, prioritize fixes, and report progress.
If your LLM citation sources’ performance feels inconsistent, these are usually the first issues to audit.
Treating AI Citations Like Backlinks
A citation is not a link-building trophy. It is evidence inside an answer. The fix is extractable claims, corroboration, and source coverage, not just more links.
Ignoring Bing
If ChatGPT sources depend heavily on Bing-powered retrieval, ignoring Bing leaves a blind spot. You may be visible in Google and absent in ChatGPT at the same time.
- Optimizing the Article Instead of the Passage
AI systems often extract passages, not page summaries. If the claim is buried, vague, or unsupported, a strong article can still lose the citation.
- Confusing Mentions With Citations
Mentions help corroboration, but they do not equal evidence. Track both, but do not report them as the same outcome.
- Skipping Corroboration
One page rarely carries the whole answer. AI systems prefer claims repeated across independent sources, so unsupported owned content usually underperforms.
Why This Is Zerply's Strategic Bet
The tooling gap in AI search is no longer about missing dashboards. It is about fragmentation. Teams doing serious AI search source analysis are often splitting work across prompt logs, spreadsheets, content docs, publishing systems, PR trackers, and analytics layers that were never designed to work together.
Zerply’s thesis is that source mapping, drafting, publishing, and AI visibility tracking should operate as one workflow.
As such, SEO Managers need prompt-to-page insight, and Digital PR Leads need source-gap visibility tied to outreach actions, while Growth Marketers need to see how citation coverage connects to pipeline signals. When those steps live in separate tools, the handoffs get slower and the signal degrades.
Source mapping is the new keyword research, and the stack should reflect that shift. The strategic bet is not that teams need more software.
It is that they need fewer disconnected systems and a tighter operating loop between discovering LLM citation sources, creating citation-ready assets, and monitoring how visibility changes across engines over time.
Start Your Source Map This Week
The fastest way to learn what shapes visibility in your category is to start logging prompts and sources now.
If you want one workflow for source mapping, drafting, publishing, and AI visibility tracking, Zerply is built to help consolidate that operating model. Start with the stack designed for this exact job and see how quickly your team can turn recurring AI citation sources into a practical worklist. Try Zerply’s 7-day free trial here.
Frequently Asked Questions (FAQs)
1. What are AI citation sources?
AI citation sources are the pages, domains, passages, and media assets an AI system uses as supporting evidence in an answer. They are different from backlinks and different from unlinked mentions because they directly shape answer construction.
2. How do I find the sources ChatGPT uses for my category?
Run real buyer prompts in ChatGPT Search, log every cited domain and URL, then repeat across problem, comparison, shortlist, and implementation prompts. The recurring sources across those runs become your category’s ChatGPT source layer.
3. How is Perplexity's citation behavior different from ChatGPT's?
Perplexity uses a more explicit multi-stage RAG pipeline with reranking and passage extraction, so structure and schema can matter more. ChatGPT also filters sources after retrieval, but Perplexity often makes the retrieval-to-citation path easier to observe.
4. How do Google AI Overviews choose their sources?
Google AI Overviews still lean heavily on ranking and query relevance, with citation probability dropping as ranking position falls. But ranking alone is not enough because clarity, corroboration, and source framing still affect what gets cited.
5. What's the difference between AI Overviews and AI Mode?
AI Overviews are a summary layer attached closely to Google’s standard search behavior. AI Mode is more exploratory, with different source presentations and stronger tendency for users to accept the shortlist without clicking out.
6. Do backlinks still matter for AI citations?
Yes, but indirectly. Backlinks can support authority and discovery, yet they do not guarantee citation. Passage quality, corroboration, structure, and source fit often decide whether a page becomes evidence.
7. How often should I audit my AI citation sources?
Monthly is a practical baseline for most categories. Source sets drift, prompt behavior changes, and competitors can expand coverage quickly, so one-off audits go stale fast.
8. Can I track AI citations in Google Search Console?
Not directly as a dedicated AI citation report. Search Console helps with visibility, clicks, and landing page context, but you still need separate prompt testing and source logging to track citations across AI surfaces.
9. How is “AI citation sources” research different from keyword research?
Keyword research shows demand. AI citation source research shows the evidence layer that answers draw from. One tells you what to target, and the other tells you where authority is being assembled.
Founder at Zerply.ai & Wittypen
Anshul is the founder of Zerply.ai and previously built Wittypen, a content marketplace powering SEO growth for 1,000+ businesses. Over the last decade he has worked hands-on with B2B SaaS and tech teams to turn search data into compounding organic growth. At Zerply he shares practical playbooks on AEO, AI visibility, and modern SEO that come directly from experiments, wins, and failures in real projects.