
ChatGPT vs Perplexity vs Google AI Overviews: How AI Platforms Cite Sources Differently

Only about 11% of cited domains overlap between ChatGPT and Perplexity, according to a Leapd analysis. That single figure explains why AI visibility is harder to diagnose than traditional SEO reporting suggests.
Citation performance sits inside a multi-stage system that includes crawl access, index eligibility, retrieval, extraction, source filtering, synthesis, and visible attribution.
That said, a page can succeed upstream and still vanish at the moment users actually see sources.
That is why ChatGPT citations, Perplexity citations, and Google AI Overview citations need separate technical analysis. Rankings still influence discoverability, but they do not explain which URL gets extracted, which passage survives synthesis, or which domain appears as a visible citation.
For SEO and AEO teams, the operational problem is clear: AI search platforms cite sources differently, and those differences compound across prompt sets, intents, and competitors.
Why Citation Behavior Matters
Citation behavior matters because the user often sees the answer before the result set. In AI interfaces, visible attribution shapes trust, recall, and click behavior even when the underlying page never wins a direct visit.
That creates a reporting layer above rankings and beside traffic, one that standard SEO dashboards rarely capture with enough precision.
The underlying system behaves like a pipeline. Ranking is one signal, retrieval is another, and visible citation is a separate outcome. Clicks come later and may never happen. And those stages can fail independently, which means a page may rank strongly, enter a candidate set, contribute context to the answer, and still receive no visible attribution.
That separation matters for planning. Editorial teams often assume strong organic positions will translate into AI visibility.
In practice, AI search platforms may prefer a tightly structured glossary, a publisher explainer, a forum thread, or a niche research page if those assets are easier to extract, fresher, or better aligned to a sub-intent.
Cross-platform divergence is the strategic issue.
Leapd found only about 11% overlap between domains cited by ChatGPT and Perplexity, and only 13.7% overlap between Google AI Overviews and Google AI Mode source sets.
Similar-looking answers can therefore be built from very different evidence pools. If reporting collapses all AI visibility into one number, teams lose the ability to see where they are winning, where they are absent, and where competitors are taking citation share.
| Also Read: How to Make SEO Content Citation-Ready for AI Answers |
The Citation Pipeline
AI citation visibility is a pipeline problem. Each stage adds its own constraints, and each platform implements those stages differently.
Pipeline stages
- Crawl access: The platform or its underlying search infrastructure must be able to fetch the page. Robots controls, blocked resources, rendering issues, or inaccessible answer content can prevent entry at the first step.
- Index eligibility: The page needs to be eligible for storage, ranking, or later retrieval. Canonicals, duplication, thin pages, and weak quality signals can reduce the odds that a URL remains available as a candidate.
- Prompt expansion: The original prompt may split into related sub-queries, reformulations, or intent branches. This matters because the cited page may match an expanded sub-question rather than the user’s exact wording.
- Candidate retrieval: The system builds a pool of possible sources. Retrieval may be search-grounded, web-browsing-assisted, or retrieval-first depending on the platform.
- Passage extraction: The platform extracts answerable passages, facts, definitions, examples, and supporting evidence from candidate pages. Passage quality often matters more than page-level relevance at this stage.
- Source filtering
Sources are filtered for quality, redundancy, freshness, authority, trust, and usefulness for the final answer. This is where many eligible pages disappear. 7. Synthesis: The model composes the answer by combining extracted evidence with model reasoning, summarization, and platform-specific output rules. 8. Visible citation: The interface decides which sources to show, link, or reference visibly. A source may influence the answer without appearing as a visible citation. 9. Click or no click: The user may click a citation, continue the conversation, refine the prompt, or leave with the answer alone. This is where visibility turns into traffic or zero-click exposure.
Where platforms diverge
ChatGPT, Perplexity, and Google AI Overviews differ at several pipeline stages.
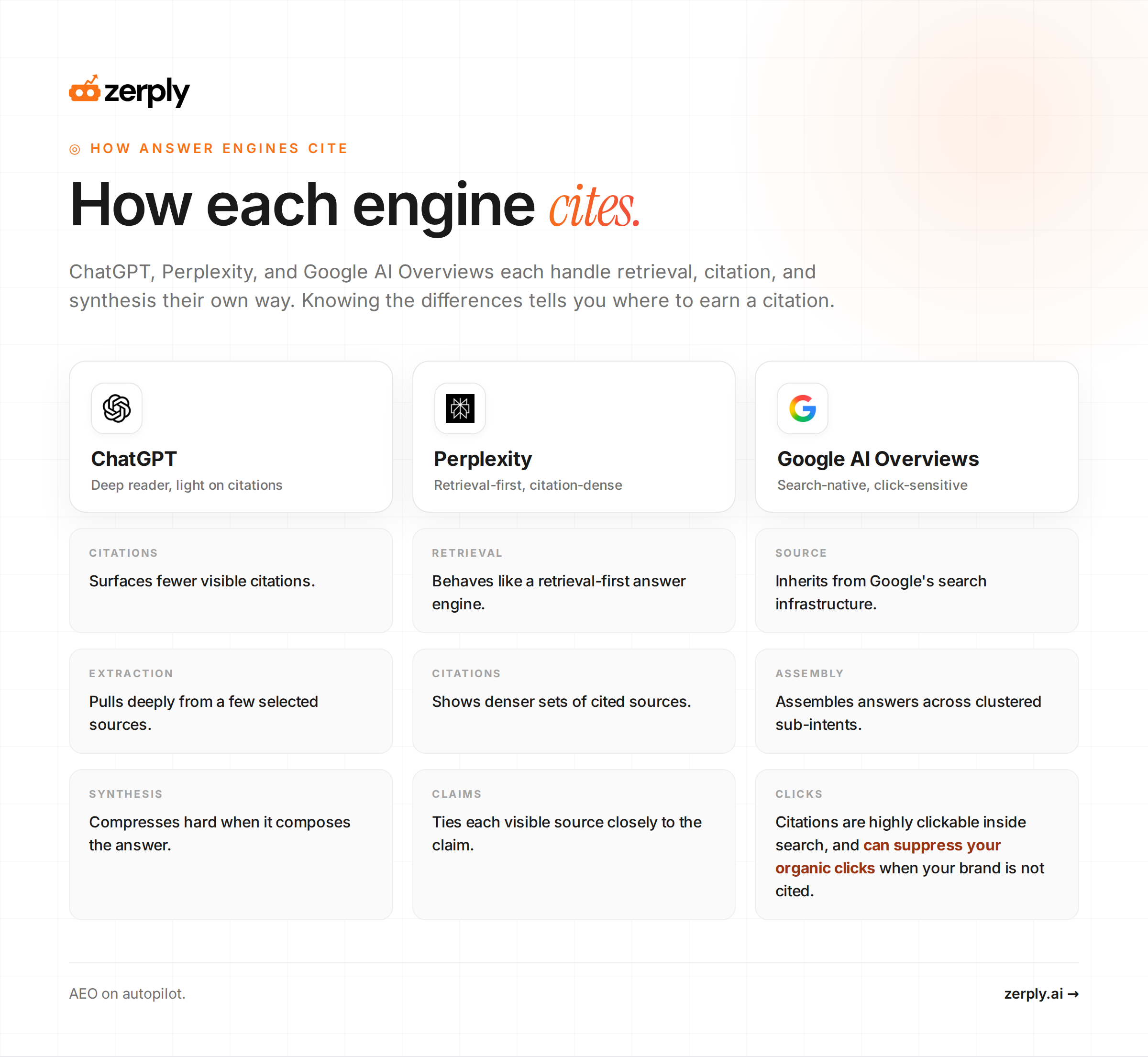
- ChatGPT tends to surface fewer visible citations, extract more deeply from selected sources, and apply stronger compression during synthesis.
- Perplexity behaves more like a retrieval-first answer engine, uses denser citation sets, and ties visible sources more closely to claims.
- Google AI Overviews inherit more from Google’s search infrastructure, often assemble answers across clustered sub-intents, and place highly clickable citations inside a search environment that can suppress organic clicks when your brand is not cited.
That makes manual diagnosis difficult. If your page is missing, the failure could come from blocked crawling, weak retrieval, poor extractability, low source trust, stronger competing passages, or simple omission at the visible citation layer.
Without platform-specific tracking, those failure modes blur together.
The benchmarks that matter
The published data already shows how different these systems are.
| Benchmark | Finding | Source |
| ChatGPT and Perplexity cited-domain overlap | 11% | Leapd |
| Google AI Overviews and AI Mode overlap | 13.7% | Leapd |
| ChatGPT average sources per answer | 6.88 | AuthorityTech |
| Perplexity average sources per answer | 16.35 | AuthorityTech |
| Perplexity average citations per response | 21.87 | Leapd |
| Google AI Overviews average sources per answer | 12.06 | AuthorityTech |
| Large-scale citation analysis | 1M citations studied | Otterly |
| Sites facing technical barriers to AI citation visibility | 73% | Otterly |
| AI Overviews reduce clicks on standard organic results | Meaningful CTR pressure on top rankings | Ahrefs |
| AI Overview prevalence and zero-click context | Rising answer-led exposure with lower click propensity | Contently |
| AIO and organic overlap | Partial, not complete | seoClarity, BrightEdge++ |
Two patterns stand out immediately.
First, citation overlap is low. If the cited-domain overlap between ChatGPT and Perplexity is only 11%, then “AI search platforms” are not one channel in any useful reporting sense.
Second, citation density varies sharply. ChatGPT averages about 6.88 sources per answer in the cited comparison, Google AI Overviews sit around 12.06, and Perplexity ranges from 16.35 to 21.87 depending on the dataset.
That changes the economics of visibility.
On a platform with fewer visible citations, each cited position is scarcer. On a platform with many citations, source share fragments faster and repeated presence becomes the more useful KPI.
Platform mechanics
- ChatGPT mechanics
ChatGPT citations are typically selective and synthesis-heavy.
In the ++AuthorityTech comparison++, ChatGPT averaged about 6.88 cited sources per answer, materially below Perplexity and below Google AI Overviews.
Fewer citations usually mean deeper extraction from each chosen source and tighter compression in the final response.
That pattern rewards pages built like reference assets.
The system tends to perform better with content that defines the topic early, answers the direct question in the opening section, uses predictable headings, and supports claims with extractable evidence.
Retrieval does not guarantee visible attribution here though.
Research on search-augmented LLMs suggests that citation quality varies heavily with provider search infrastructure and retrieval design, not model capability alone, as discussed in ++arXiv research on citation variance++.
A page may be present in the candidate pool and still fail in the later stages because another source offers a cleaner definitional passage, less ambiguity, or stronger consensus language.
That is why ChatGPT citations often skew toward semantically complete, reference-style pages rather than broader thought-leadership pieces.
A direct explainer with a concise answer block, stable terminology, visible authorship, and source-linked evidence is easier to extract from than an opinion article that approaches the subject indirectly.
- Perplexity mechanics
Perplexity citations reflect a more retrieval-first architecture.
The platform tends to fan out across a larger source set, preserve stronger claim-to-source traceability, and keep citations prominent inside the interface.
The numbers are the clearest indicator.
++AuthorityTech++ found about 16.35 sources per answer, while ++Leapd++ reported an average of 21.87 citations per response in a larger sample.
++Otterly’s 1M-citation study++ supports the broader conclusion that retrieval-first answer engines cite more densely and distribute visibility across more domains.
That changes optimization priorities.
As such, Perplexity often rewards:
- recent updates
- explicit external sourcing
- tightly scoped FAQ and how-to sections
- evidence-rich claims
- corroboration from third-party sites, publishers, forums, and expert communities
Google AI Overview mechanics
Google AI Overviews sit closer to classic search infrastructure, yet citation behavior still diverges from ranking order.
Organic strength matters, but it is only one input. Google can assemble an overview from pages that satisfy different sub-intents within the same query cluster.
This matters because AI Overviews often operate through retrieval and synthesis across related intents, not one literal keyword match.
A page may be cited because it answers a supporting sub-question cleanly, not because it ranks first for the head term. That helps explain why overlap with classic top rankings is meaningful but incomplete, as shown by ++seoClarity++and ++BrightEdge](https://www.brightedge.com/resources/weekly-ai-search-insights/rank-overlap-after-16-months-of-aio)++).
Google’s citation density sits between ChatGPT and Perplexity. AuthorityTech++ reported roughly 12.06 sources per answer for Google AI Overviews.
The click economics are especially important.
++Ahrefs++ found meaningful CTR pressure on top organic listings when AI Overviews appear, and ++Contently++ adds context around prevalence and zero-click behavior.
For Google AI Overview citations, the strongest pages usually combine organic strength, strong entity consistency, structured markup where appropriate, and broad intent coverage across the cluster.
Ranking, Retrieval, and Citation
A useful technical model separates four layers:
| Layer | Question | Typical failure |
| Ranking | Does the page perform in classic search | Weak SEO fundamentals |
| Retrieval | Can the system pull the page into candidate sets | Crawl, index, or relevance issues |
| Citation | Does the platform show the source visibly | Poor extraction, filtering loss, stronger competitors |
| Click outcome | Does the citation earn traffic | Zero-click behavior or weak snippet appeal |
This is where LLM citation behavior becomes measurable instead of abstract.
If the page ranks but never enters AI answers, investigate retrieval.
If it appears in retrieval or answer context but remains uncited, inspect extraction quality, evidence formatting, and platform fit.
If it is cited but traffic stays flat, the issue may be click dynamics rather than citation loss.
Relevant work on citation fidelity and source reliability in generated answers, including ++arXiv findings on citation behavior++, reinforces the need to audit visible citations directly rather than assume the system represented the source accurately.
Metrics to Track
Manual checking breaks down fast unless teams define clear formulas.
| Metric | Formula | Why it matters |
| Citation rate | cited answers ÷ tracked prompts | Shows how often your brand earns visible citations |
| Citation share of voice | brand citations ÷ all tracked citations in a prompt set | Measures competitive presence in the citation layer |
| Citation gap | competitor citations − brand citations for the same prompt set | Quantifies where competitors out-cite you |
| Cited-page coverage | unique cited URLs ÷ priority URLs | Shows how much of your target content actually earns citations |
| Platform citation divergence | citation share difference across ChatGPT, Perplexity, and Google AI Overviews | Reveals platform-specific gains and losses |
A few practical examples make the formulas useful.
- If your brand is cited in 24 of 100 tracked prompts, your citation rate is 24%.
- If your brand receives 36 citations out of 180 total citations across a prompt cluster, your citation share of voice is 20%.
- If Competitor A receives 52 citations and your brand receives 31 across the same prompt set, your citation gap versus that competitor is 21.
- If 18 of 60 priority URLs have appeared as visible citations, your cited-page coverage is 30%.
- If your citation share is 28% in ChatGPT, 11% in Perplexity, and 19% in Google AI Overviews, you have a significant platform citation divergence that should drive content and diagnostic work.
These metrics only become reliable when segmented by platform, prompt set, cited URL, source type, and time period.
What the Numbers Reveal
The real value of measurement is diagnosis.
| Pattern | Likely cause | What to inspect |
| High rank but no AI citation | Good SEO performance, weak extraction or platform mismatch | Answer blocks, heading structure, passage clarity, evidence formatting, schema, prompt-intent fit |
| Retrieved but uncited | Candidate inclusion without surviving source filtering or visible attribution | Competing cited passages, trust signals, claim specificity, source redundancy, citation position rules |
| Cited in ChatGPT but missing in Perplexity | Strong reference structure, weak freshness or limited corroboration | Update cadence, external references, community discussion, narrow FAQ coverage |
| Cited in Perplexity but missing in AIO | Fresh evidence page without enough organic strength or intent breadth | Organic rankings, entity consistency, sub-intent coverage, internal linking, brand authority |
| AIO present but no brand citation | Google synthesized answer from other sources in the cluster | Query cluster coverage, SERP overlap, cited competitor pages, CTR loss by query group |
| Competitor cited repeatedly | Competitor has stronger extractable assets or broader citation footprint | Their cited URLs, page templates, evidence style, schema, update rhythm, third-party mentions |
This is also where technical constraints become visible.
++Otterly++ found that 73% of sites in its research showed technical barriers that could weaken AI crawler access or citation eligibility.
So if the baseline infrastructure is broken, content changes alone will not fix citation loss.
What Makes Content Citable
Citable content performs across the whole pipeline.
Technical eligibility
Start with access and interpretability.
If important answer content depends on fragile rendering, blocked resources, or inconsistent canonicals, retrieval quality drops before source selection even begins.
Technical audits should confirm:
- crawler access for search and relevant AI-facing fetch paths
- rendered visibility of the main answer content
- canonical consistency across duplicates
- schema alignment with page type
- stable internal linking to priority reference pages
Given Otterly’s finding that ++73%++ of sites face technical barriers in this area, this step deserves more attention than it usually gets.
Extractable structure
Passage extraction favors pages that expose answers clearly. Strong candidates usually include:
- a concise answer block near the top
- headings that map to real user questions
- entity naming that stays consistent
- source-linked evidence
- visible author and update information
- short paragraphs that preserve meaning when extracted
This is especially important for ChatGPT citations, where fewer cited sources mean each selected passage must carry more of the answer.
Fresh evidence
Perplexity citations often improve when pages include updated stats, dates, methods, source links, and narrower question scope.
On evidence-heavy topics, a stale but authoritative page can lose to a newer and better-documented source.
Intent coverage
Google AI Overviews often reward pages that answer the head query plus adjacent sub-questions.
This is why category explainers, brand resource hubs, and comprehensive informational pages can outperform a narrowly optimized article in overview citations.
A Platform-specific Playbook
| Platform | Strong page type | Strongest signal | Common failure | Best diagnostic |
| ChatGPT | Reference pages, glossaries, structured explainers | Extractable, semantically complete passages | Retrieval without visible attribution | Compare retrieval presence to visible citation rate |
| Perplexity | Research posts, narrow FAQs, evidence-led explainers | Freshness, source traceability, corroboration | Citation share diluted across many sources | Track repeat appearance and share of voice |
| Google AI Overviews | Intent-cluster resources, brand explainers, category hubs | Organic grounding plus sub-intent coverage | Organic visibility without AIO citation | Compare ranking overlap, citation presence, and CTR impact |
For ChatGPT
- Build durable reference pages.
- Tight definitions, direct answers, and low-friction extraction improve the odds of visible citation.
- If pages are often relevant but rarely cited, inspect passage-level clarity and whether competing pages express the same idea more cleanly.
For Perplexity
- Ship narrower, more current, and better-sourced pages.
- Add dates, methods, external references, and corroborating evidence.
- Track citation frequency across many prompts because one-off wins matter less when the platform cites so broadly.
For Google AI Overviews
- Strengthen organic foundations while expanding cluster coverage.
- Use schema where it supports page interpretation, reinforce entity consistency, and compare AIO citation presence against organic rank and CTR movement.
Why Manual Tracking Fails
Manual checking sounds manageable until the scope becomes clear. Citation visibility must be segmented by:
- platform
- prompt set
- topic cluster
- cited URL
- citation type
- competitor presence
- share of voice
- change over time
A few screenshots or ad hoc prompt checks cannot tell you whether a page was missing because it was never retrieved, filtered out during source selection, displaced by a competitor, or simply omitted from visible attribution in one platform but not another.
How Zerply Helps Up Your Citation Game
AI citations is where an operating layer becomes necessary.
Zerply helps by turning citation tracking into a structured workflow instead of a manual exercise. It gives teams a way to monitor:
- AI visibility by platform
- visible citation counts and citation rate
- citation share of voice by prompt set
- citation gaps versus competitors
- which URLs are actually earning citations
- trend lines over time across ChatGPT, Perplexity, and Google AI Overviews
That matters because AI citation analysis is only useful when it is comparable and repeatable.
Teams need to know whether a visibility drop came from one platform or all three, whether the loss affected one URL or an entire topic cluster, and whether competitors gained share while the brand stood still.
A platform like Zerply makes those patterns visible in a way random prompt checking never will.
For SEO and AEO practitioners, the practical takeaway is simple. Citation visibility now sits in its own measurement layer, and that layer has to be monitored with the same discipline applied to rankings, crawl health, and content performance.
FAQs
How should teams measure ChatGPT citations
Use a tracked prompt set and calculate citation rate, share of voice, cited-page coverage, and trend over time. Separate visible citation from general answer appearance so retrieval or mention without attribution does not inflate reporting.
Why are Perplexity citations usually higher
Perplexity tends to use a retrieval-first workflow with denser source fan-out and stronger source-to-claim traceability. That is why studies cited above report materially higher average source counts than ChatGPT.
Do Google AI Overviews cite top-ranking pages
Sometimes. Research from ++seoClarity++and ++BrightEdge](https://www.brightedge.com/resources/weekly-ai-search-insights/rank-overlap-after-16-months-of-aio)++) shows partial overlap, not full overlap. A lower-ranked page can still be cited if it answers a sub-intent better.
What causes a page to be retrieved but uncited
The page may enter the candidate pool yet lose during passage extraction, source filtering, or visible attribution. Weak answer formatting, unsupported claims, stale evidence, or stronger competing passages are common causes.
Does schema improve AI citation performance
Schema can improve interpretability and eligibility, especially in Google AI Overviews, but it works best when paired with clear answer structure, strong evidence, technical accessibility, and intent coverage.
What is the fastest useful KPI set
Start with citation rate, citation share of voice, citation gap, and cited-page coverage. Break each metric out by ChatGPT, Perplexity, and Google AI Overviews so platform citation divergence becomes visible.
Founder at Zerply.ai & Wittypen
Anshul is the founder of Zerply.ai and previously built Wittypen, a content marketplace powering SEO growth for 1,000+ businesses. Over the last decade he has worked hands-on with B2B SaaS and tech teams to turn search data into compounding organic growth. At Zerply he shares practical playbooks on AEO, AI visibility, and modern SEO that come directly from experiments, wins, and failures in real projects.